
Esta guía explica cómo configurar OpenCode con Ollama en una GPU local, elegir modelos GGUF adecuados y ajustar el tamaño de contexto para programar sin depender de servicios externos.
Introducción
Por el aumento de costes de las grandes IA y por la necesidad de proteger datos sensibles, experimentar con OpenCode sobre una GPU local empieza a tener mucho sentido. En mi caso, hacerlo desde un equipo de la LAN ya está dando resultados viables.
Voy a ir pasando a limpio las partes relevantes de mis notas de trabajo para facilitar el camino a quien quiera experimentar con ello. El artículo está sujeto a errores y actualizaciones. Las notas por ahora están incompletas, lo que no las hace menos útiles si sabes un poco lo que llevas entre manos.
El entorno de prueba y los criterios de elección
No necesitas exactamente este hardware para aprovechar la guía. Estos son los datos de mi entorno de prueba, útiles como referencia para interpretar los resultados de velocidad, VRAM y offloading. Con otro equipo, la lógica será la misma, cambiarán los modelos viables, el tamaño de contexto y la paciencia necesaria para obtener el mejor resultado viable.
Esto daría para un artículo completo, quizá para varios. Resumámoslo en ciertos detalles que extenderé en otro momento.
Mi entorno de prueba
GPU usada
Utilizo una NVIDIA GeForce RTX 4070 Ti Super, elegida por lo más relevante: tiene 16 GB de VRAM. Elige la mayor cantidad de VRAM posible como criterio principal una vez te hayas decantado por usar AMD o NVIDIA.
Estos valores son solamente orientativos: el resultado real dependerá del modelo elegido, su cuantización, el tamaño de contexto configurado y la tolerancia a que parte de la carga termine en CPU o RAM.
- 8 GB de VRAM: suficientes para un entorno principalmente experimental, con modelos pequeños, cuantizaciones ajustadas y contexto limitado.
- 12 GB de VRAM: permiten empezar a trabajar con modelos viables bien cuantizados, aunque obligan a moderar expectativas en tamaño de modelo, longitud de contexto y velocidad.
- 16 GB de VRAM: un punto especialmente interesante para utilizar modelos más ambiciosos mediante ajustes finos, como en el caso descrito en este artículo.
- 24 GB de VRAM o más: ofrecen mucho más margen para aumentar el tamaño del modelo o del contexto, con menor necesidad de offloading y una experiencia más fluida.
RAM usada
En mi caso uso 32 GB DDR5 en 2 módulos de 16 GB para aprovechar el doble canal. Como orientación práctica, disponer de al menos el doble de RAM que de VRAM ayuda a mantener un flujo de trabajo fluido. DDR4 también puede servir, DDR5 simplemente ofrece más margen y mejor rendimiento sin anclarse en tecnologías que van quedando atrás.
Almacenamiento recomendado
Este puede ser un cuello de botella según para qué uses el equipo pues cambiar de modelo requiere de un tiempo de carga que va limitado muchas veces por la unidad de almacenamiento. Los SSD NVMe son lo más recomendable.
El tamaño de la unidad depende de si vas a usar el servidor de inferencia para más cosas y si vas a experimentar mucho con él o vas muy directo a producción. Para programación y texto, con 512 GB irás bien, si requieres ya múltiples trabajos en imagen y vídeo no bajes de 1 TB.
Los modelos son grandes consumidores de espacio de almacenamiento, no pierdas el rastro de los que ya no utilices.
Software utilizado
Para la inferencia, estoy utilizando Ollama por su flexibilidad y la facilidad de uso. Utilizar llama.cpp también es una fantástica elección.
Si Ollama corre en un equipo de la LAN distinto al de OpenCode, asegúrate de que el servicio escucha en la interfaz adecuada, no solamente en 127.0.0.1; por ejemplo, con OLLAMA_HOST=0.0.0.0:11434. Limita el acceso con firewall/VPN y no expongas Ollama a Internet sin protección.
El modelo
La elección del modelo es uno de los puntos críticos. La cantidad de VRAM condiciona buena parte de la decisión, pues de ella dependerá que el modelo y su contexto puedan ejecutarse íntegramente en la GPU o que parte de la carga tenga que mantenerse en la RAM y procesarse con la CPU, el llamado offloading con la consecuente pérdida de velocidad. En Ollama, este reparto puede comprobarse con ollama ps: cuanto mayor sea la proporción ejecutada en GPU, mejor suele ser el rendimiento. No es lo mismo esperar medio minuto por una respuesta simple que ver cómo una tarea requiere una hora y media de proceso. Aquí empieza el juego de equilibrismo que requirió de muchas horas de experimentación para entender lo que conviene en la práctica, que en mi opinión, dista de algunas recomendaciones simplificadas que he visto por ahí.
No podemos tomar la decisión basándonos en un único criterio, lo que aprietas por un lado se afloja por el otro.
Modelo base
Demasiado pequeño y será rápido y tonto, demasiado grande y será desesperadamente lento. Unos comentarios orientativos, me basé en los modelos Qwen pues tienen muy buena fama en programación y las pruebas que hice lo confirman. Eso no quita que pueda haber otros interesantes para actividades concretas o modelos que encajen mejor con las características de tu equipo, la VRAM disponible o tus gustos personales.
En IA local para programación, el mejor modelo no es el más grande: es el más grande que puedas ejecutar sin convertir cada respuesta en una penitencia.
Qwen 2.5 Coder 7B. Lo lamento, un modelo de 7B de parámetros no alcanza para programar. Quizás pequeños scripts, cositas muy supervisadas o experimentos para tomar soltura sean viables.
Qwen 3 14B: Probablemente mejor que su antecesor Qwen 2.5 Coder 7B, lo considero lo mínimo utilizable como punto de partida.
DeepSeek Coder v2 16B: Apenas lo he probado, lo había experimentado anteriormente en VSCode con la extensión Continue y me convencía más Qwen 3 14B.
GPT OSS 20B: Si consigues una versión que funcione bien, debería ser viable.
Qwen 3.6 27B: Esto empieza a ser serio, me da confianza para trabajar seriamente con él y con mucho apuro y afinando al máximo he logrado que funcione, es mi elección actual. Es un modelo denso (monolítico) al contrario que el siguiente que es un MoE (mezcla de expertos).
Qwen 3.6 35B A3B: Fantástico, un MoE que solo utiliza expertos de 3B en cada momento. Lamentablemente, demasiado grande para mi VRAM, la velocidad colapsa estrepitosamente. Es posible que la calidad real final no mejore la del modelo 27B.
Qwen 3 Coder Next 80B: Deberás comprobar tu edad para saber si terminas el proyecto antes de jubilarte o si acabas gastando tanto en GPU como en un coche… o más.
A igualdad de volumen de parámetros, es preferible siempre la versión más moderna del mismo origen, por ejemplo, Qwen 3 14B sobre Qwen 2.5 Coder 14B o Qwen 3.6 27B sobre Qwen 3.5 27B.
Tu opinión sobre otros modelos puede ser un enorme aporte, no dejes de comentar sobre los que has probado para bien y para mal.
La cuantización
Es el siguiente punto crítico que se combina con la elección del modelo. Llegar a estas conclusiones viene tras muchas horas de pruebas y anotaciones.
Una recomendación que he visto repetidamente y con la que no estoy nada de acuerdo es utilizar versiones cuantizadas en 3 bits tipo Q3_XXS. Claro, reduces mucho el uso de VRAM y quizás te puedes permitir un modelo mayor que de otro modo, ¿pero a qué precio? Una vez te pones a aplicarlo en un uso real, observas que con cierta frecuencia aparecen caracteres cambiados que dan al traste con el código generado y las correcciones requeridas lastran largamente el flujo de trabajo. Eso sin contar con las veces que el error no sea detectado y pase a ser un bonito bug.
Para programar, desaconsejo los modelos cuantizados en 3 bits: están fuera de los límites de lo tolerable. Quizás si solo pretendes hacer HTML o documentar, sea viable.
Observemos las opciones de cuantización de Bartowski para Qwen 3.6 27B. Para una GPU de 16 GB son muy deseables y tentadoras.
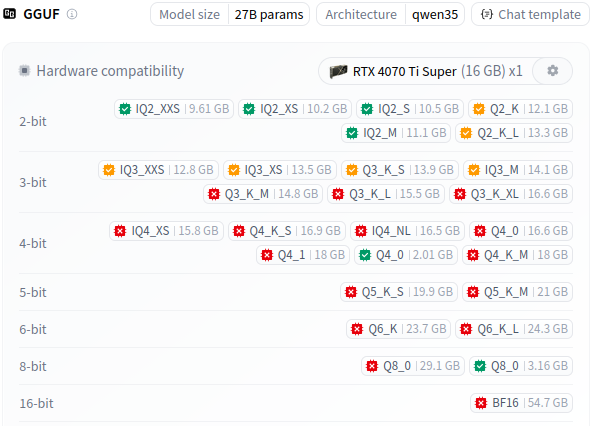
Los 4 bits han sido durante mucho tiempo una referencia habitual para cuantizar modelos de generación de texto, Q4_K_M es lo que suele entregar Ollama en la mayoría de modelos de forma genérica, en ese criterio coincidimos.
Pero… hay veces que necesitamos una chispita más, el Q4_K_M hace demasiado offloading y no deja trabajar seriamente, acabas antes haciendo todo a mano. Un IQ4_NL es una finura que con la cuantización imatrix y la no linealidad, para programación es preferible respecto a una IQ4_XS y muy similar a una Q4_K_M. Ten presente que el comentario de sus desarrolladores recomendando IQ4_XS es con texto y no con programación en mente. Si el servidor de inferencia soporta esa cuantización (en el momento de escribir este artículo aún había ciertas incompatibilidades solucionables con trabajo) puede ofrecer una reducción de tamaño muy valiosa. Cuando estás rozando el límite de la VRAM, unos pocos cientos de MB pueden marcar una diferencia enorme.
Pero no basta, sigue siendo desesperadamente lento. ¿Podríamos rascar otros pocos MB más para reducir offloading y aumentar velocidad? Pues hay quien hace maravillas y en ggufbench lograron reducirlo de un modo mucho más artesanal, nada de cuantizaciones estándar automatizadas. Os traduzco lo que dicen los artistas porque soy incapaz de explicarlo:
Estrategia de cuantización consciente de la arquitectura
Qwen 3.6 27B es un modelo híbrido Mamba/Transformer. No todas las capas cumplen la misma función, y no todos los tensores toleran la cuantización por igual. Esta distribución respeta la arquitectura al:
- Reducir la precisión de los tensores resilientes, como embeddings y FFN gate/up, cuando la sensibilidad KLD es plana y la pérdida de calidad es imperceptible.
- Proteger las capas de atención pura (
blk.3,7,11...63) con mayor precisión para el razonamiento global y el enfoque de largo alcance. - Comprimir de forma agresiva las capas híbridas dominadas por SSM, donde el estado recurrente soporta la carga secuencial.
- Preservar los tensores críticos de enrutamiento y proyección en precisión nativa o casi nativa para evitar la acumulación de errores.
¿El resultado? El tamaño del archivo baja a 12.6 GB.
Victoria, eso es un Qwen 3.6 27B plenamente usable en 16 GB de VRAM. Ya tengo el modelo que quería, no he de conformarme con un 14B o seguir peleando con el GPT OSS 20B: «¡Trata de arrancarlo, Carlos!».
El tamaño de contexto
Dependiendo del tamaño del proyecto y de la complejidad de las acciones requeridas, la necesidad es variada.
Un par de truquitos para el contexto
Sin confundir con la cuantización del modelo pues son cosas totalmente independientes, utilizar la caché K/V (clave/valor) del contexto en 8 bits con q8_0 en lugar de en los 16 bits originales reduce aproximadamente a la mitad la memoria consumida sin pérdida de calidad perceptible. Bajarla a 4 bits con q4_0 puede reducirla a una cuarta parte aprox. respecto a f16 si bien ahí ya hay más posibilidades de pequeñas diferencias en la precisión de uso del contexto.
Dependiendo del uso es un buen aliado, si activas Flash Attention puedes pasar la caché de contexto K/V a 8 bits con esta configuración en el override del servicio de Ollama si usas Linux o en algún otro lugar según sea tu sistema operativo o instalación, pasando la variable de entorno a Ollama.
Para editar el archivo de override /etc/systemd/system/ollama.service.d/override.conf, que se mantendrá aun cuando actualices Ollama, utiliza:
sudo systemctl edit ollamaAhí puedes agregar, dentro de la sección [Service] lo siguiente:
[Service]
Environment="OLLAMA_FLASH_ATTENTION=1"
Environment="OLLAMA_KV_CACHE_TYPE=q8_0"Aplica cambios y comprueba que no aparecen errores en el log con:
sudo systemctl daemon-reload
sudo systemctl restart ollama
systemctl show ollama --property=Environment
journalctl -u ollama -n 40 --no-pagerOtro truquito interesante: no necesitas quedarte ligado a un único tamaño de ventana de contexto. Puedes crear distintas variantes del mismo modelo y utilizar la más conveniente en cada momento. Eso sí: no cambies a una variante con menos contexto disponible mientras la sesión actual todavía lo necesite. Compacta o reduce primero el contexto; de otro modo, podrías impedir la compactación automática y dejar la sesión bloqueada.
¿Cómo configurar el tamaño de la memoria de contexto?
El máximo de memoria de contexto utilizable es una característica propia del modelo. En una ocasión al menos observé una cuantización que reducía ese máximo.
Con GPUs de menos de 24 GB de VRAM, Ollama suele utilizar por defecto 4k tokens de contexto. Para trabajar seriamente con OpenCode en proyectos reales, ese contexto resulta insuficiente. Como estamos apurando el uso de la VRAM y tratando de minimizar el offloading para no pasarle más trabajo del imprescindible a la CPU que luego eterniza el tiempo de inferencia, volvemos al equilibrismo, ya el final. Como he comentado anteriormente, no necesitamos atarnos a una memoria de contexto concreta, así que podemos crear varias configuraciones en OpenCode como si fueran modelos diferentes. Estas configuraciones vendrán de variaciones que podemos crear en Ollama.
Necesitamos primero tener el modelo ya descargado en Ollama:
ollama pull hf.co/ggufbench/Qwen3.6-27B-4bpw-16GB-VRAMConfiguración de tools y otras incompatibilidades
Podemos encontrarnos con que modelos cuantizados obtenidos en Hugging Face hayan perdido características por el camino. En este caso, no funcionan las herramientas (tools) si empleas Ollama v0.24.0 o anterior y esto es un fracaso completo en OpenCode, son imprescindibles. No pasa nada, si tomas el modelfile del Qwen original, las recuperas.
ollama pull qwen3.6:27bHe creado un directorio ~/.ollama/modelfiles/ donde guardar los modelfile personalizados y no perderlos. Allí creo versiones con nuevas limitaciones de contexto y además, con menos temperatura pues los programadores toman cafés, no carajillos.
Por ejemplo, para crear una versión con 256k de contexto, primero copio el original de Qwen y así ya recupero las tools:
ollama show --modelfile qwen3.6:27b > ~/.ollama/modelfiles/qwen3.6-27b-4bpw-256k.modelfileEditando el nuevo archivo, cambio la referencia de origen para que apunte al modelo cuantizado de ggufbench y no al Qwen que originalmente entrega Ollama que después podré borrar. Hay que cambiar el FROM por:
FROM hf.co/ggufbench/Qwen3.6-27B-4bpw-16GB-VRAMOtros cambios son bajar la temperatura y ajustes varios para su uso como agente programación con modo thinking, como se especifica para la versión específica para programación de Qwen 3.6 27B Coding mxfp8:
PARAMETER temperature 0.6
PARAMETER top_p 0.95
PARAMETER top_k 20
PARAMETER min_p 0.0
PARAMETER repeat_penalty 1.0
PARAMETER presence_penalty 0
Parte de estos parámetros acabarán siendo sobrescritos por OpenCode en tiempo de ejecución.
Y por último, añadimos la indicación de contexto de 256k que remplaza a los 4k que Ollama considera por defecto con las GPU de menos de 24 GB de VRAM. A partir de 24 aplica 32k y con 48 o más GB de VRAM, ya son 256k. Con un comando ollama ps mientras usas el modelo confirmas el valor que realmente se está empleando.
PARAMETER num_ctx 262144Con el modelfile preparado, creamos la variante del modelo en Ollama. Algo que sea lógico y reconocible:
ollama create qwen3.6-4bpw:27b-256k -f ~/.ollama/modelfiles/qwen3.6-27b-4bpw-256k.modelfileAsí ya disponemos en Ollama de un modelo llamado qwen3.6-4bpw:27b-256k que no duplica el archivo pesado del modelo porque reutiliza el archivo descargado de ggufbench.
Antes de hacer la caché K/V en 8 bits, en diferentes momentos obtuve estos valores usando esa variante:
NAME ID SIZE PROCESSOR CONTEXT
qwen3.6-4bpw:27b-256k b8a903e1ccb2 36 GB 61%/39% CPU/GPU 262144
qwen3.6-4bpw:27b-256k b8a903e1ccb2 36 GB 57%/43% CPU/GPU 262144Mucho uso de CPU, el contexto devora la VRAM y estamos como al comienzo.
Por el mismo método creé dos variantes adicionales, una de 64k (65536) y otra de 128k (131072). Ya con la K/V caché en 8 bits, el cambio es brutal:
NAME ID SIZE PROCESSOR CONTEXT
qwen3.6-4bpw:27b-64k 279bc70395de 16 GB 9%/91% CPU/GPU 65536Eso ya es plenamente utilizable: el offloading es perceptible, pero pequeño. He hecho alguna pequeña intervención como prueba.
La recomendación oficial es utilizar una ventana de contexto mínima de 64k. He probado creando una versión con contexto de 32k (32768) y pese a la alegría de verlo caber en la GPU, en la práctica no es funcional.
Si necesitas cambiar de versión de Ollama para experimentar o por algún problema, primero apagas Ollama y el comando de instalar/actualizar en Linux es, para la estable:
curl -fsSL https://ollama.com/install.sh | shy, para una versión concreta, por ejemplo, la Release Candidate 31 de la v0.30.0:
curl -fsSL https://ollama.com/install.sh | OLLAMA_VERSION=0.30.0-rc31 shPara entender lo que sucede y poder comparar, tienes dos amigos: nvitop y ollama ps.
Ahora lo que falta es configurarlos en OpenCode, por el procedimiento normal como si fueran modelos diferentes. En mi instalación independiente, la configuración está en ~/.opencode/opencode.json.
nano ~/.opencode/opencode.jsonSi utilizas el OpenCode lanzado o configurado desde Ollama, probablemente trabajes con ~/.config/opencode/opencode.json.
ollama launch opencode --configAtento a la IP del servidor de Ollama, no es lo mismo si está en el mismo equipo que tiene OpenCode (localhost) que si está en otro equipo de la LAN.
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"ollama": {
"npm": "@ai-sdk/openai-compatible",
"name": "Ollama (local)",
"options": {
"baseURL": "http://127.0.0.1:11434/v1"
},
"models": {
"hf.co/ggufbench/Qwen3.6-27B-4bpw-16GB-VRAM": {
"name": "Qwen 3.6 27B 4bpw 16GB VRAM",
"tools": true
},
"qwen3.6-4bpw:27b-64k": {
"name": "Qwen 3.6 27B 4bpw 64k",
"tools": true
},
"qwen3.6-4bpw:27b-128k": {
"name": "Qwen 3.6 27B 4bpw 128k",
"tools": true
},
"qwen3.6-4bpw:27b-256k": {
"name": "Qwen 3.6 27B 4bpw 256k",
"tools": true
}
}
}
},
"model": "qwen3.6-4bpw:27b-64k"
}
Si Ollama está en otro equipo de la LAN, sustituye 127.0.0.1 por la IP de ese servidor.
Obviamente puedes incluir más modelos, he hecho limpieza en ese ejemplo. Solo recuerda que el bloque con el último modelo ya no lleva la coma tras la llave. El modelo que se indica al final en model es el que arrancará por omisión.
¡Y a trabajar!
cd ~/mis_proyectos/proyecto_1
opencodeComprobar que funcionan las tools es tan simple como en modo plan, pedirle en un prompt: Lista los archivos de este directorio sin modificarlos.
Si no lo vas a utilizar, borra el Qwen original desde el que obtuviste el modelfile, ya no lo necesitas.
ollama rm qwen3.6:27bDos vueltas de tuerca adicionales
Trabajando ya con una versión estable de Ollama 0.30, en lugar de las versiones candidatas que utilicé inicialmente, la configuración se mantiene estable y conserva este reparto de carga:
NAME ID SIZE PROCESSOR CONTEXT
qwen3.6-4bpw:27b-64k 279bc70395de 16 GB 9%/91% CPU/GPU 65536Es una lástima que ese 9 % de offloading a CPU ralentice el funcionamiento. Bajar a 32k de contexto permite que todo entre en GPU, pero en mis pruebas queda demasiado corto para trabajar cómodamente con OpenCode. Ahora que ya estoy trabajando sobre una versión estable, me lanzo al ajuste final.
Contexto de 48k
He probado una opción intermedia, que la vida no se limita al binario y las potencias de dos. Si en 64k va bien y en 32k queda corto, siendo además que podemos tener configuradas variantes diversas y cambiarlas sin salir de OpenCode con /models, he creado una variante de 48k de contexto y la he puesto como modelo por defecto en OpenCode. He copiado el de 64k y con él creado un nuevo ~/.ollama/modelfiles/qwen3.6-27b-4bpw-48k.modelfile al que le cambio simplemente el contexto.
PARAMETER num_ctx 49152Aplicarlo para crear la nueva variante del modelo no tiene misterio, esto ya se hizo antes.
ollama create qwen3.6-4bpw:27b-48k -f ~/.ollama/modelfiles/qwen3.6-27b-4bpw-48k.modelfileEl resultado se acerca pero no llega al éxito rotundo deseado.
NAME ID SIZE PROCESSOR CONTEXT
qwen3.6-4bpw:27b-48k 9a72c7cd1606 15 GB 5%/95% CPU/GPU 49152Es un acelerón, se nota diferencia. Estando tan cerca de la victoria, es una lástima no conseguir que toda la carga quede en GPU, sin offloading a CPU. No voy a bajar a 32k, porque empezaría a tener problemas por falta de contexto, ni a reducir la caché K/V a q4_0, porque en tareas de programación con contextos largos prefiero evitar la pérdida adicional de precisión que puede introducir. En mis pruebas, incluso pequeñas inconsistencias en nombres de archivo o fragmentos de código ya resultan molestas, así que afino por otro punto.
Reducir el tamaño del lote del prompt
Cuando el prompt es largo, algo habitual en OpenCode al trabajar con historial, instrucciones y archivos del proyecto, Ollama no lo procesa de una sola vez, sino por lotes. En mi instalación, el valor predeterminado observado para num_batch es 512 tokens. Reducir ese lote puede ralentizar ligeramente la lectura inicial del contexto, pero también disminuye el pico de memoria necesario para procesarlo. Si con ello se elimina el offloading a CPU, la ganancia final puede ser muy superior.
num_batches un parámetro avanzado disponible en Ollama y comprobable en su API/código actual, aunque no aparece recogido en la tabla pública principal de parámetros del Modelfile. Por ello conviene verificar su comportamiento si se cambia de versión.
Regresamos a editar el modelfile en ~/.ollama/modelfiles/qwen3.6-27b-4bpw-48k.modelfile y agregamos la reducción a la mitad del tamaño del lote de prompt:
PARAMETER num_batch 256Recreamos esa variante del modelo:
ollama create qwen3.6-4bpw:27b-48k -f ~/.ollama/modelfiles/qwen3.6-27b-4bpw-48k.modelfileSi estaba en uso, reiniciamos Ollama para que tome el nuevo:
sudo systemctl restart ollamaSi no lo hemos hecho antes, agregamos el modelo de 48k en el ~/.opencode/opencode.json o archivo equivalente. Aprovecho para declarar en OpenCode una salida máxima de 8k tokens. De este modo, OpenCode conoce el margen que debe reservar para que el modelo pueda responder y compactar la conversación antes de agotar la ventana disponible.
"qwen3.6-4bpw:27b-48k": {
"name": "Qwen 3.6 27B 4bpw 48k",
"tools": true,
"limit": {
"context": 49152,
"output": 8192
}
},Ahora han quedado recortadas las características. La pregunta correcta es ¿Ha merecido la pena? Comprobar el proceso con ollama ps proporciona la respuesta.
NAME ID SIZE PROCESSOR CONTEXT
qwen3.6-4bpw:27b-48k 9fa4efa5f5d3 15 GB 100% GPU 49152¡100 % en GPU, sin offloading a CPU!
Dejo configurado este modelo por defecto porque elimina el offloading a CPU y ofrece la mejor velocidad práctica en mi equipo; cuando necesite más contexto, siempre puedo cambiar desde OpenCode a las variantes de 64k, 128k o 256k.
2 respuestas a «Cómo usar OpenCode con Ollama y una GPU local»
Yo estoy probando algunos modelos más, concretamente estoy teniendo buenos resultados con Qwen3-Coder-30B-A3B-Instruct-IQ4_XS, con 32k de contexto y kv q8_0.
Es un archivo de más de 16 GB, ¿asumes el offloading en una GPU de 16 GB manteniendo un resultado digno?